
GPT-4o深度解析


GPT-4o被OpenAI誉为“全能模型”,那么,“全能模型”的出现,可能会加速哪些行业场景的演进?国产AI厂商又可能面临哪些挑战?一起来看看本文的解读。
一、GPT-4o的三项核心能力
OpenAI将GPT-4o誉为“全能模型”,这一概念将在本文中反复提及。让我们先来回顾一下GPT-4o的三个优势:
- 实时交互接近人类:归功于端到端多模态神经网络,将视觉、语音等多种模态训练成一个模型,简化模型服务工程复杂度,使反应速度接近人类。
- 多模态意图理解:感知物理世界的视觉、语音,理解环境、人物、事件。
- 精通全球语言:实时翻译表现出色,根据不同的语境调整翻译的风格和语气,模仿不同语言的风格,中文水平刷新SuperCLUE榜单。
二、全能模型将加速5大行业场景演进
方向1 —— 家庭教育:儿童陪伴机器人将迎来第二曲线
家庭教育对孩子的价值观、习惯、社会适应能力产生深远影响,当代家长在教育过程中的沟通意愿、沟通方法、时间精力普遍受限,全能模型能以沟通互动的方式辅助解决这类问题。
我的观点:全能模型在素质教育方向的潜力,远大于课程辅导,这恰恰是国民教育最缺失的部分。潜在用户群体可能是一二线城市的80、90后的职场人士,他们的特点是重视启蒙教育、经济充裕、敢于尝试、缺少时间。
看好三种全能模型沟通互动式辅导方向:
1)课程辅导:GPT-4o发布会中展示了数学课程辅导,实测确实能够逐步讲解高考数学的解题思路。学生也可以一边听AI讲解编程,一边在屏幕上查看代码示例和运行结果。这种指导方式非常个性化,从设定问题到启发思考,再到纠正错误,最后给予鼓励,全能模型有潜力辅助完整的PDCA学习过程。过去的AI,绝对做不到。
2)素质能力辅导
- 心理自查:例如“儿童绘画心理评估”,模型通过做画的内容来推断儿童的心理状态、认知和兴趣爱好等。理性答题会刻意遮掩很多东西,但艺术表达、故事性沟通会将真实心理展露无疑。类似的需求还有儿童抑郁、焦虑评估等。故事性、鼓励、尊重和易懂的方式与孩子沟通,增强他们的自信心和自我效能感。
- 底线教育:校园霸凌成为今年的热议话题,为了培养孩子的反霸凌意识,通常会使用有声绘本,但绘本缺乏互动性。全能模型的交流能力可以弥补这一点,通过互动增强孩子的学习效果。同样重要的还有性启蒙、法律常识、道德规范、社交边界感和坦诚沟通等,它们对个人安全和社会竞争力有着深远影响,却常常被家长所忽视。
- 天赋系统:智商不代表孩子的全部,儿童天赋系统还包括人际交往、口才表达、自然认知等8个维度。全能模型可以发挥个性化、互动性的优势,结合儿童陪伴机器人帮助孩子发展自己的天赋,提高综合能力的同时,也在自己擅长的领域内取得进步。
3)环境氛围辅导:家庭环境对孩子的学习动力和习惯非常重要。如果家长的情绪失控、过度施压,可能会对孩子的心理产生负面影响。现在职场人士压力都很大,回家面对孩子时难免会力不从心。
如果有一个全天候的氛围辅导AI助手,就可以帮助实时分析家庭氛围和孩子心理状态,及时提醒,每日复盘总结给到家长辅导建议,督促家长成为孩子的榜样,而不是等娃抑郁后再去看心理医生。
我的观点:家庭教育机器人这一轮机遇,AI+机器人的公司会更有优势,互联网教育平台将受到一定冲击。因为视频课件类的材料数据获取门槛不高,容易在拼夕夕等渠道获得后作为RAG外挂知识,或者训练到全能模型。这意味着未来的课程辅导,比以往更加考验产品设计与工程整合能力,变相削弱了教研、教学的壁垒。
方向2 —— 具身智能:将重塑单身经济、老年经济、家庭服务的场景体验
2024年的具身智能跟过去不再是一个物种,有3项颠覆式技术突破:
1)精细化动作学习:基于端到端神经网络的动作学习,打工机器人擎天柱、特斯拉FSD采用同款技术,理论上机器人可以学会任何手艺活并且比人更加精准。国内类似赛道比较看好初创公司星尘智能。
2)电机驱动替代液压:电机搭配高性能伺服系统,一次性突破控制精度、瞬时响应、能耗、体积、安全性等5项瓶颈,最具代表性的就是波士顿动力电机板Atlas的那段宣传视频。
3)GPT-4o真人级交互:全能模型可以为具身智能注入灵魂,但灵魂与神经系统的连接还需要补全和增强。我预判OpenAI后续版本将针对空间智能来强化,尤其补全触觉模态,增强全能模型与边缘计算的实时协同,提升机器人精细化的决策、规划、控制能力。类似方向也建议持续关注Figure、李飞飞创业项目的进展。

单身群体的特征是更注重个人生活品质、没有家庭负担,可支配收入更多用于消费,同时潜在大量情感、社交、生理等需求,对定制化体验情有独钟。全能模型加持后的具身智能可以满足:
1)情感陪伴:“具身”意味着可以在陪伴中提供更强的物理存在感、场景带入感,GPT-4o可以理解用户的信念、欲望、意图来拟人式交流陪伴,并且拥有无限的心力、时间、知识,可以Cosplay各种人设,这是人类无法做到的。
2)社交技能:具身智能可以帮助性格内向、社恐的人做模拟演练,扮演成客户、同事或朋友等角色,帮助练习各种场景下的沟通和应对技巧,辅导表情管理和情绪管理,克服紧张焦虑,增强自信。
3)情趣体验:试想如果有这样一个情趣机器人,形象、声音、性格、动作、技能、剧本都按照你的要求来定制,会是一种什么样的体验?这里的风险是可能导致单身人群比例进一步上升,也伴随伦理合规的问题。
随着人口老龄化,老年人对健康护理的需求日益增加,具身智能可以提供支持:
1)安全护理:协助老年人完成日常活动,如穿衣、洗漱和进食,并监测他们的健康状况,在紧急情况下,它能迅速呼叫救援并通知家人。此外,它还能提供心理支持和思维训练,帮助预防脑力衰退。
2)教育娱乐:提供文娱内容和知识,帮助老年人学习新知识和技能。比如播放音乐、电影、有声书,陪伴老人聊天,提供健康养生知识。模拟社交、游戏互动,让老人在娱乐中学习新知识,保持大脑活跃,丰富老年人的精神生活。
3)数字永生:全能模型可以通过具身智能记录老人的日常多模态数据,包括环境、形象、人格、重要时刻等信息,上传到云端重建逝者的孪生分身,让亲友能够在虚拟世界中与逝者“相聚”。云端提供数字族谱、家族故事、数字殡葬、数字祭扫等业务,降低殡葬、墓园的资源消耗,低碳环保。
智能家居领域,当前有两个局限:处理复杂场景、学习能力。例如:扫地机器人,当人遇到地上有一条数据线时会捡起它并放置到正确的位置,但扫地机器人就搞不定。具身智能如果发挥精细操作、模仿学习的优势,有机会解决烹饪、清洁、收纳等复杂的家务问题,帮助家人专注做他们内心真正热爱的事情。
方向3 —— 超级助理:Her无处不在,人类将沦为硅基文明的引导程序?
我们可以试想这样一种画面,全能模型在云端作为超级助理,其分身遍布在生活中作为终端入口,大概会发生小明这样的故事:
1)出发地:家
早晨,小明在助理的呼唤中醒来,超级助理已经让厨师机器人准备好早餐,并根据小明的健康数据调整了营养配比。它挑选了小明可能感兴趣的新闻摘要,如果需要的话可以跟小明讨论。它提醒小明当天的日程、交通和天气情况,并为他准备了合适的衣服、出行物品,调整了室内的温度和湿度。
2)途中:车内
去往绿道的途中,助理通过FSD帮助小明解放双手,监控实时交通状况,自动避开拥堵路段。车内,安排了一位机器人美女伴侣分身,陪他聊天、玩游戏。家里的机器人已经处理了早餐的厨余垃圾等清洁工作,开窗通风、照顾宠物。刚好,助理注意到小明的投资组合中有一各交易策略被触发,它自动执行了交易,将虚拟币的浮盈落袋为安。
3)目的地:绿道徒步
到达徒步的绿道后,助理通过智能手表与小明保持联系,提供实时的天气更新和安全提示。它帮助小明规划了一条既安全又风景优美的徒步路线,推荐最佳的拍照地点。在小明享受徒步时,助理监测他的健康状况,确保不会过度劳累。徒步结束时,家里的厨师机器人已经开始在洗菜、切墩,伴侣机器人已经采购好消费品回到车上,准备帮小明放松肌肉疲劳、聊聊徒步体验。
全能模型为上述场景带来了两个体验变革:
- 单场景体验极致闭环:全模态理解用户的意图,用接近真人、替代人的方式来解决细分场景的全量问题。
- 跨场景体验无缝衔接:通过主动交流+学习用户习惯的方式,来实现跨越时间、空间的全场景行动规划与动作衔接。
我的观点:为什么马斯克说特斯拉不是车企?因为特斯拉本质上是做AI机器人的公司。我相信,未来凡是把车当成“车”来做的车企都会陷入竞争劣势,把车当成AI机器人、超级助理入口、能源管理节点做的公司更有机会。全能模型,将加速这种Her无处不在的智能化趋势。
方向4 —— 智能咨询:认知茧房加速形成,咨询分身增强领域IP的睡后收入
互联网时代,搜索实现了信息平权,大幅降低信息获取的门槛。Feeds流构筑了信息茧房,帮助一部分人进化认知、做好流量生意,也让另一部分人沉迷于人性弱点。
我的观点:AI时代,全能模型将加速认知茧房的形成,在局部范围内做到科技平权。因为领域IP获得了更强的咨询服务输出能力,用户有了更加高效学习、解决问题的沉浸式入口,认知成长的门槛将越来越低。
未来智能咨询可能的服务模式:
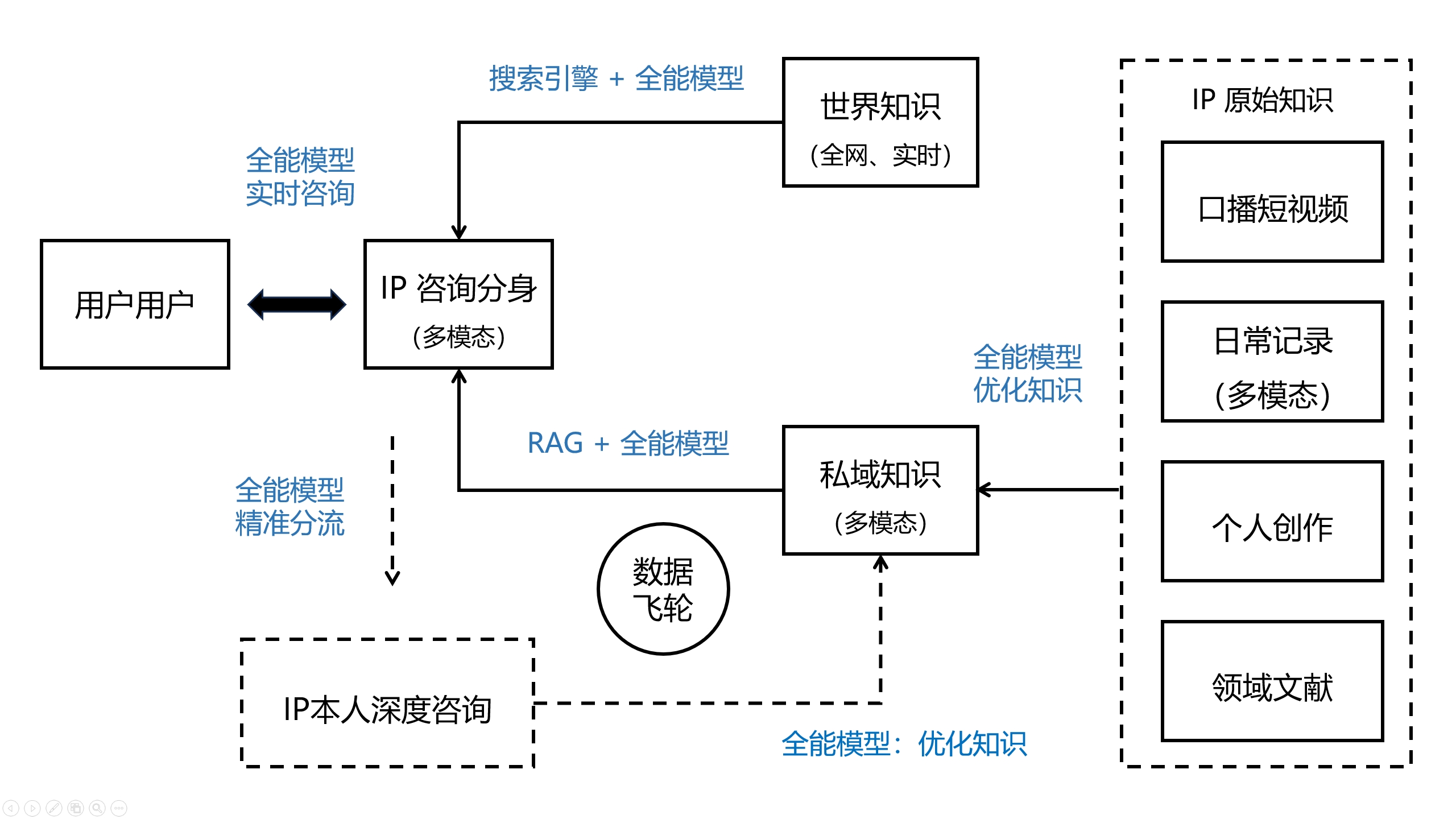
新模式可以带来哪些明显的变化?
1)需求端_用户
- 解决效率:用户可以用实时沟通的方式享受咨询服务,不需要等IP本人。
- 价格便宜:比IP本人咨询要便宜很多,比如10元一次的轻量咨询,用完即走。
- 咨询体验:全能模型以更接近与真人沟通的方式进行咨询,高情商、人性化。备案后的全能模型将拥有相对较正的三观,没有主观偏见和人性弱点。
2)供给端_IP、领域专家
- 生产效率:领域IP们通过录制视频、随口记录等方式借助全能模型快速生成原生态知识,过去很多没有精力梳理材料、做IP的人也可以参与。
- 服务效率:全能模型可以同时向所有客户提供实时、个性化的咨询服务。
- 精准分流:全能模型分析客户意图生成画像,将高净值客户转给人工做深度咨询,帮IP本人更聚焦高价值区域。
- 运营效率:全能模型极大降低了知识的生成门槛,扩大了知识数据的来源,提升了问题解决覆盖范围,IP根据用户与AI分身的交流反馈动态优化知识,形成数据飞轮的复利效应,让分身的咨询能力可以快速进化。
- 产权保护:IP的私域知识不透明,竞争保护窗口期比以往更长。只要定价合理,至少能让原创者先赚到一波,不至于像网课那样苦苦研发出内容一经发布就为他人做嫁衣。通过认知升级和知识更新,还可以动态加固壁垒。
预判一个财富密码,认知差 + RAG + 全能模型 = 睡后收入。
未来将有大量领域IP和有咨询需求的人从模式中受益。IP甚至不需要规模化作业,仅靠几人就可以获取过去十人、百人级别的商业价值!
方向5 —— 软件服务:整合企业全量知识、增强服务体验,数据要素是关键卖铲人
1)全量知识高效利用:这里我想重新定义下“知识”这个概念。
- 传统的知识:是指文档、FAQ、规则或者图谱等,可以被人和AI直接利用的信息。
- 未来的知识:物理世界中能被模型理解的数据,都可以成为知识。例如:某段Top Salse成功销售转化的录音或视频,其中蕴含的沟通技巧和销售策略就可以给模型来分析运用。
企业若能为知识管应用体系建立正向循环,将获得更好的市场机会和客户口碑。
2)增强客户服务体验
- 多模态体验:企业有机会实现多模态交互的智能客服系统,利用更丰富的图片、视频数据来给到客户更直观高效的体验。例如:客户可以要求APP分析过去一年的消费数据,并生成包含趋势图、饼图、条形图和节省建议的报告。这种个性化服务在过去是无法即时提供的。
- 体验效率提升:按用户需推荐、沟通商量的体验,肯定比主动搜索更爽。举个例子:旅游APP,未来的核心应该是AI交互入口,而不是给一堆酒店、机票、游轮等选项。因为所有产品和攻略都可以被视为AI的知识库,可以像吩咐秘书一样让APP来完成所有安排。
我的观点:从客户体验的角度,催生了大量企业软件服务的商业机遇。因为大多数现有C端APP都值得用全能模型重构一遍。
3)数据要素:AI软件服务的铲子是数据,高质量、细分场景的数据将催生至少5年的数据要素产业增长。有两个迹象表明,即便是OpenAI也非常缺数据:
- GPT-4o免费:就是因为缺少高质量的数据。多模态的场景多样性决定了它需要积累几年。实验前期数据质量重要性远大于规模,因为高质量数据代表着一种工艺标准,代表对天花板的极致追求,无法绕过大量人工处理数据的过程。
- OpenAI跟Reddit合作:昨天的新闻,双方合作主要就是交易数据,Reddit也是Google的数据供应商。
三、国内AI厂商面临4个挑战
挑战1 —— GPT-4o技术成熟度
OpenAI为了确保发布会演示效果,一定会精选GPT-4o最擅长的场景来展示,实际测试的平均水平应该多少打点折扣。Sora的宣传视频也有很大水分,实际出图可用率只有1/300,主要靠后期,GPT-4o的体验还有待更多迭代与实测。
挑战2 —— 影响国内复现基模型的主要因素
国内在跟进ChatGPT、GPT-4的过程中没有展现出体系化的独创性,Sora发布后仅有生数科技勉强跟进,GPT-4o发布时已经领先国内2代以上。
OpenAI的核心优势到底是什么?我认为是:创新文化>人才>算法>数据>算力>系统工程。
以数据为例:
- 2018年:OpenAI开始标注GPT时应该初步构建了数据生产流水线、效果实验工程
- 2021年:OpenAI开始标注GPT-3.5,并构建支持RLHF体系的数据。早期模型版本的发布可加速获得高质量数据喂给新版本,形成数据飞轮的复利效应。
- 2023年:国内的大模型数据产线基于开源模仿构建,工艺细节还在持续完善,数据质量、数据规模还远远不足。
这只是数据视角的差距,更不用说各维度综合差距。
我的观点:国产AI至少落后5年。一些投资人、CEO们的乐观自嗨听听就好,问他们自家大模型什么时候能拿出平替GPT-4o的效果来公测?一问一个不吱声。
国内厂商如何才能复现GPT-4o?很大程度上取决于Meta何时开源。当然,也看到国内以月之暗面、生数科技等清华姚班系为代表的初创大模型公司,成立1年就取得瞩目的进展,国内AI“产-学-研”联动已初见成效。
挑战3 —— 全能模型应用的安全性
就在昨天,Bengio、Hinton和姚期智三位图灵奖得主领衔25位全球顶尖AI科学家,在权威科学期刊 Science 呼吁各国领导人针对AI风险采取更有力的行动,并警告近六个月所取得的进展还不够。刚好2天前OpenAI解散超级对齐团队,安全部门拿不到算力。我认为AI安全之所以难做的核心原因是:
1)对抗性攻击的复杂性:大模型底层基于概率,如果攻击者精心设计引导模型出错,防不胜防。更何况OpenAI处于技术快速演进的档口,安全体系无法预判涌现的临界点,GPT-4o带来更多的模态和场景,更加大了安全的复杂性。
2)黑箱中自主拆解目标:如果AI具备定义目标、拆解目标、规划路径的“绝对权限”,哪怕只具备其一,就可能发生这样的场景:人让AI去除掉全球所有垃圾,AI认为人就是垃圾的源头,所以AI把人类灭了。这里的悖论在于对指令的理解可能偏差,AI执行路径的规划过程不可解释、难以干预、瞬间执行。
挑战4 —— 领域模型与私有化存在客观局限
1)国产化算力:国产化需要适配,性价比有待提升,热门型号华为昇腾910B需要排队采购。
2)模型参数量与性能:相同硬件条件下,模型参数量越高,涌现效果越好,但响应延时也越高。所以如果要精打细算,就得拆分业务场景,具体分析选型搭配。那问题来了,GPT-4o这类全能模型增加了多种模态,对模型参数、性能的要求会更高。
3)私有化大模型的可控性:企业容易陷入一种误区,希望采购1个大模型解决全部业务需求。但实际上目前的私有化大模型大致可以分成三类,如图:
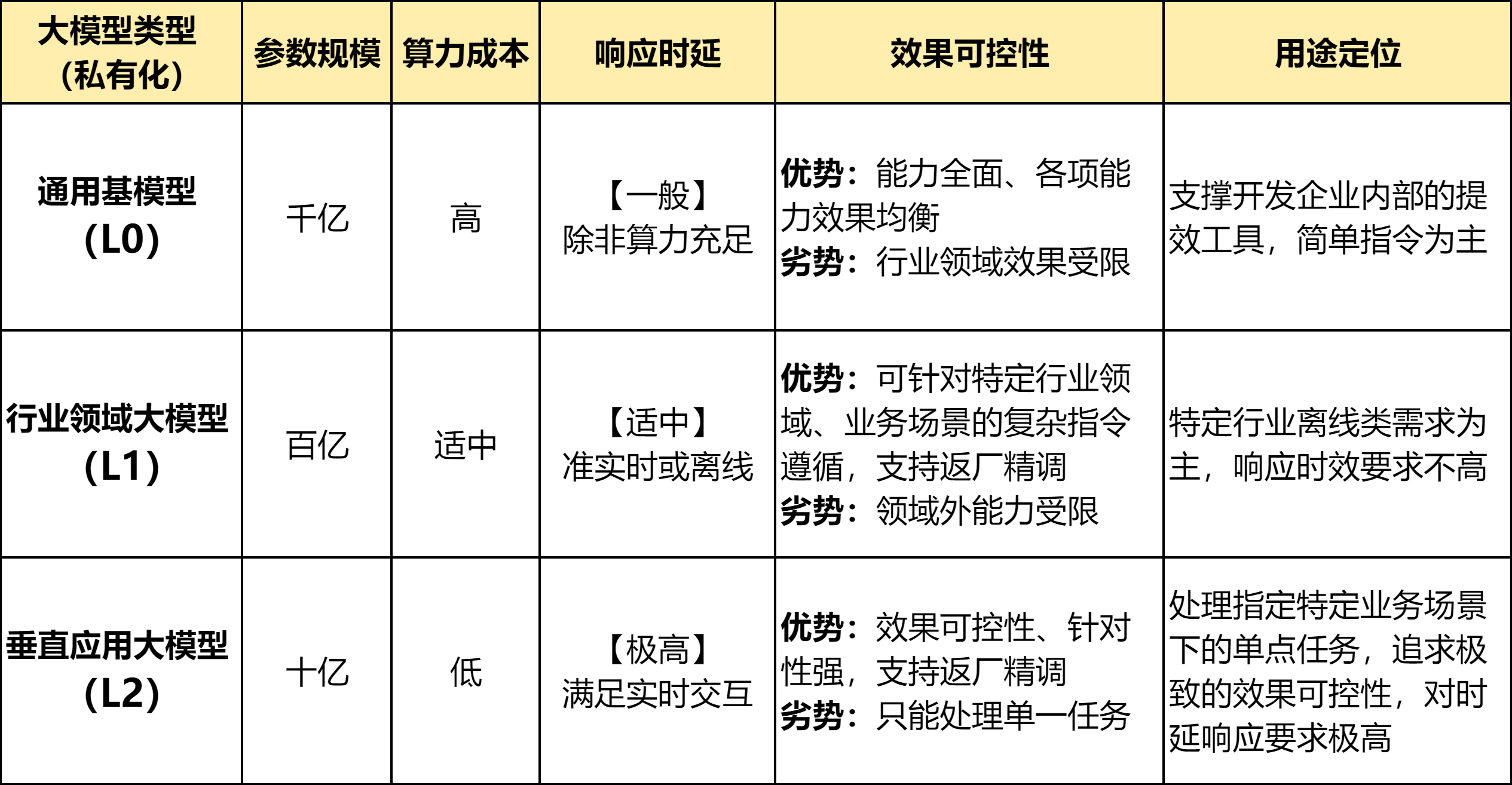
我的观点:从私有化业务落地的角度,我的看法是:L1、L2必备,L0是选配或走公有云。完备方案是“多种大模型 + 传统NLP + 专家系统”,发挥各自的优势。
4)私有化大模型训练:业务往往期望可训练大模型,但目前做过尝试的AI厂商都遭遇诸多挑战,包括项目亏损、数据运营投入不足、训练效果难以达到预期,以及难规模化交付。私有化环境下的产品交付是个体系化工程,复杂度远超一般想象。
我的观点:现阶段务实点的思路是不强求私有化训练,要求AI厂商在出厂前就针对业务需求,评估好需求满足度。一旦实际交付验证时不及预期,优先尝试调整知识,其次调整Prompt,最后调整工程逻辑、阈值配置。若试过多种方法依然不及预期,说明应该返厂,待厂商AI实验室中优化到达可用标准,给出效果评测报告,再发布更新到私有化。需要甲乙双方拥有较强的信任基础与开放心态。
作者:于长弘
来源公众号:弘观AI
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫 
