
AI大模型实战篇


在这篇文章中,将为大家介绍可能是目前最强大的AI Agent设计框架,集多种规划和反思技术的集大成者,LATS。文章内容会相对比较复杂难懂,值得收藏和反复研读。

一、LATS的概念
LATS,全称是Language Agent Tree Search,说的更直白一些,LATS = Tree search + ReAct + Plan&Execute+ Reflexion。这么来看,LATS确实非常高级和复杂,下面我们根据上面的等式,先从宏观上拆解一下LATS。
1. Tree Search
Tree Search是一种树搜索算法,LATS 使用蒙特卡罗树搜索(MCTS)算法,通过平衡探索和利用,找到最优决策路径。
蒙特卡罗方法可能大家都比较熟悉了,是一种通过随机采样模拟来求解问题的方法。通过生成随机数,建立概率模型,以解决难以通过其他方法解决的数值问题。蒙特卡罗方法的一个典型应用是求定积分。假设我们要计算函数 f(x) 在[a, b]之间的积分,即阴影部分面积。

蒙特卡罗方法的解法如下:在[a, b]之间取一个随机数 x,用 f(x)⋅(b−a) 来估计阴影部分的面积。为了提高估计精度,可以取多个随机数 x,然后取这些估计值的平均值作为最终结果。当取的随机数 x 越多,结果将越准确,估计值将越接近真实值。

蒙特卡罗树搜索(MCTS)则是一种基于树结构的蒙特卡罗方法。它在整个 2^N(N 为决策次数,即树深度)空间中进行启发式搜索,通过反馈机制寻找最优路径。MCTS 的五个主要核心部分是:
- 树结构:每一个叶子节点到根节点的路径都对应一个解,解空间大小为 2^N。
- 蒙特卡罗方法:通过随机统计方法获取观测结果,驱动搜索过程。
- 损失评估函数:设计一个可量化的损失函数,提供反馈评估解的优劣。
- 反向传播线性优化:采用反向传播对路径上的所有节点进行优化。
- 启发式搜索策略:遵循损失最小化原则,在整个搜索空间上进行启发式搜索。
MCTS 的每个循环包括四个步骤:
- 选择(Selection):从根节点开始,按照最大化某种启发式价值选择子节点,直到到达叶子节点。使用上置信区间算法(UCB)选择子节点。
- 扩展(Expansion):如果叶子节点不是终止节点,扩展该节点,添加一个或多个子节点。
- 仿真(Simulation):从新扩展的节点开始,进行随机模拟,直到到达终止状态。
- 反向传播(Backpropagation):将模拟结果沿着路径反向传播,更新每个节点的统计信息。

2. ReAct
ReAct的概念和设计模式,风叔在此前的文章中《AI大模型实战篇:AI Agent设计模式 – ReAct》已做过详细介绍。
它的典型流程如下图所示,可以用一个有趣的循环来描述:思考(Thought)→ 行动(Action)→ 观察(Observation),简称TAO循环。
- 思考(Thought):面对一个问题,我们需要进行深入的思考。这个思考过程是关于如何定义问题、确定解决问题所需的关键信息和推理步骤。
- 行动(Action):确定了思考的方向后,接下来就是行动的时刻。根据我们的思考,采取相应的措施或执行特定的任务,以期望推动问题向解决的方向发展。
- 观察(Observation):行动之后,我们必须仔细观察结果。这一步是检验我们的行动是否有效,是否接近了问题的答案。
- 循环迭代

3. Plan & Execute
Plan & Execute的概念和设计模式,风叔同样在此前的文章中《AI大模型实战篇:AI Agent设计模式 – Plan & Execute》已做过详细介绍,因此不再赘述。
Plan-and-Execute这个方法的本质是先计划再执行,即先把用户的问题分解成一个个的子任务,然后再执行各个子任务,并根据执行情况调整计划。

4. Reflexion
Reflexion的概念和设计模式,风叔在上篇文章《AI大模型实战篇:Reflexion,通过强化学习提升模型推理能力》做了详细介绍。
Reflexion的本质是Basic Reflection加上强化学习,完整的Reflexion框架由三个部分组成:
- 参与者(Actor):根据状态观测量生成文本和动作。参与者在环境中采取行动并接受观察结果,从而形成轨迹。前文所介绍的Reflexion Agent,其实指的就是这一块
- 评估者(Evaluator):对参与者的输出进行评价。具体来说,它将生成的轨迹(也被称作短期记忆)作为输入并输出奖励分数。根据人物的不同,使用不同的奖励函数(决策任务使用LLM和基于规则的启发式奖励)。
- 自我反思(Self-Reflection):这个角色由大语言模型承担,能够为未来的试验提供宝贵的反馈。自我反思模型利用奖励信号、当前轨迹和其持久记忆生成具体且相关的反馈,并存储在记忆组件中。智能体利用这些经验(存储在长期记忆中)来快速改进决策。

因此,融合了Tree Search、ReAct、Plan & Execute、Reflexion的能力于一身之后,LATS成为AI Agent设计模式中,集反思模式和规划模式的大成者。
二、LATS的工作流程
LATS的工作流程如下图所示,包括以下步骤:
- 选择 (Selection):即从根节点开始,使用上置信区树 (UCT) 算法选择具有最高 UCT 值的子节点进行扩展。
- 扩展 (Expansion):通过从预训练语言模型 (LM) 中采样 n 个动作扩展树,接收每个动作并返回反馈,然后增加 n 个新的子节点。
- 评估 (Evaluation):为每个新子节点分配一个标量值,以指导搜索算法前进,LATS 通过 LM 生成的评分和自一致性得分设计新的价值函数。
- 模拟 (Simulation):扩展当前选择的节点直到达到终端状态,优先选择最高价值的节点。
- 回溯 (Backpropagation):根据轨迹结果更新树的值,路径中的每个节点的值被更新以反映模拟结果。
- 反思 (Reflection):在遇到不成功的终端节点时,LM 生成自我反思,总结过程中的错误并提出改进方案。这些反思和失败轨迹在后续迭代中作为额外上下文整合,帮助提高模型的表现。

下图是在langchain中实现LATS的过程:
第一步,选择:根据下面步骤中的总奖励选择最佳的下一步行动,如果找到解决方案或达到最大搜索深度,做出响应;否则就继续搜索。
第二步,扩展和执行:生成N个潜在操作,并且并行执行。
第三步,反思和评估:观察行动的结果,并根据反思和外部反馈对决策评分。
第四步,反向传播:根据结果更新轨迹的分数。

三、LATS的实现过程
下面,风叔通过实际的源码,详细介绍LATS模式的实现方法。关注公众号【风叔云】,回复关键词【LATS源码】,可获取LATS设计模式的完整源代码。
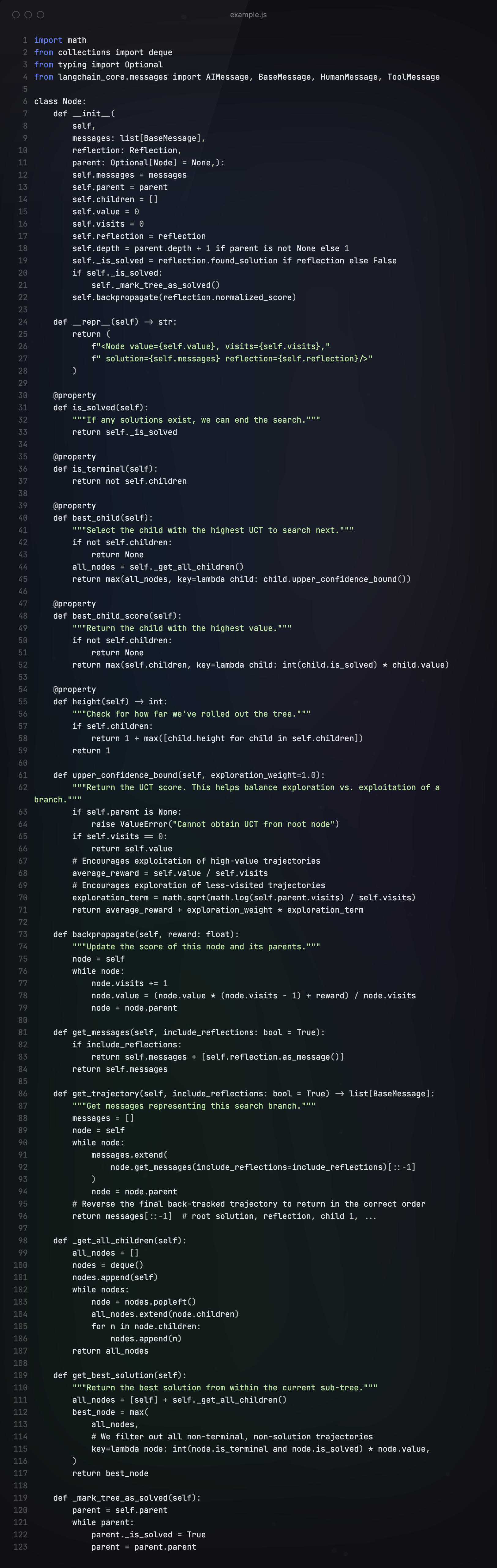
第一步 构建树节点
LATS 基于蒙特卡罗树搜索。对于每个搜索步骤,它都会选择具有最高“置信上限”的节点,这是一个平衡开发(最高平均奖励)和探索(最低访问量)的指标。从该节点开始,它会生成 N(在本例中为 5)个新的候选操作,并将它们添加到树中。当它生成有效解决方案或达到最大次数(搜索树深度)时,会停止搜索。
在Node节点中,我们定义了几个关键的函数:
- best_child:选择 UCT 最高的子项进行下一步搜索
- best_child_score:返回具有最高价值的子项
- height:检查已经推进的树的深度
- upper_confidence_bound:返回 UCT 分数,平衡分支的探索与利用
- backpropogate:利用反向传播,更新此节点及其父节点的分数
- get_trajectory:获取代表此搜索分支的消息
- get_best_solution:返回当前子树中的最佳解决方案
第二步 构建Agent
Agent将主要处理三个事项:
- 反思:根据工具执行响应的结果打分
- 初始响应:创建根节点,并开始搜索
- 扩展:从当前树中的最佳位置,生成5个候选的下一步
对于更多实际的应用,比如代码生成,可以将代码执行结果集成到反馈或奖励中,这种外部反馈对Agent效果的提升将非常有用。
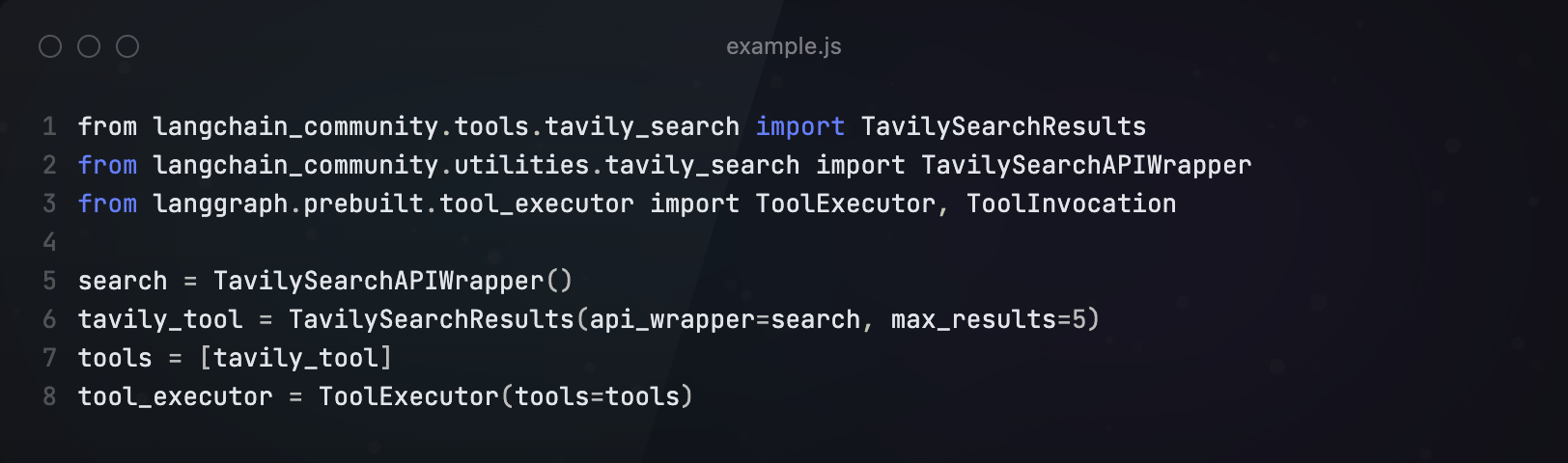
对于Agent,首先构建工具Tools,我们只使用了一个搜索引擎工具。
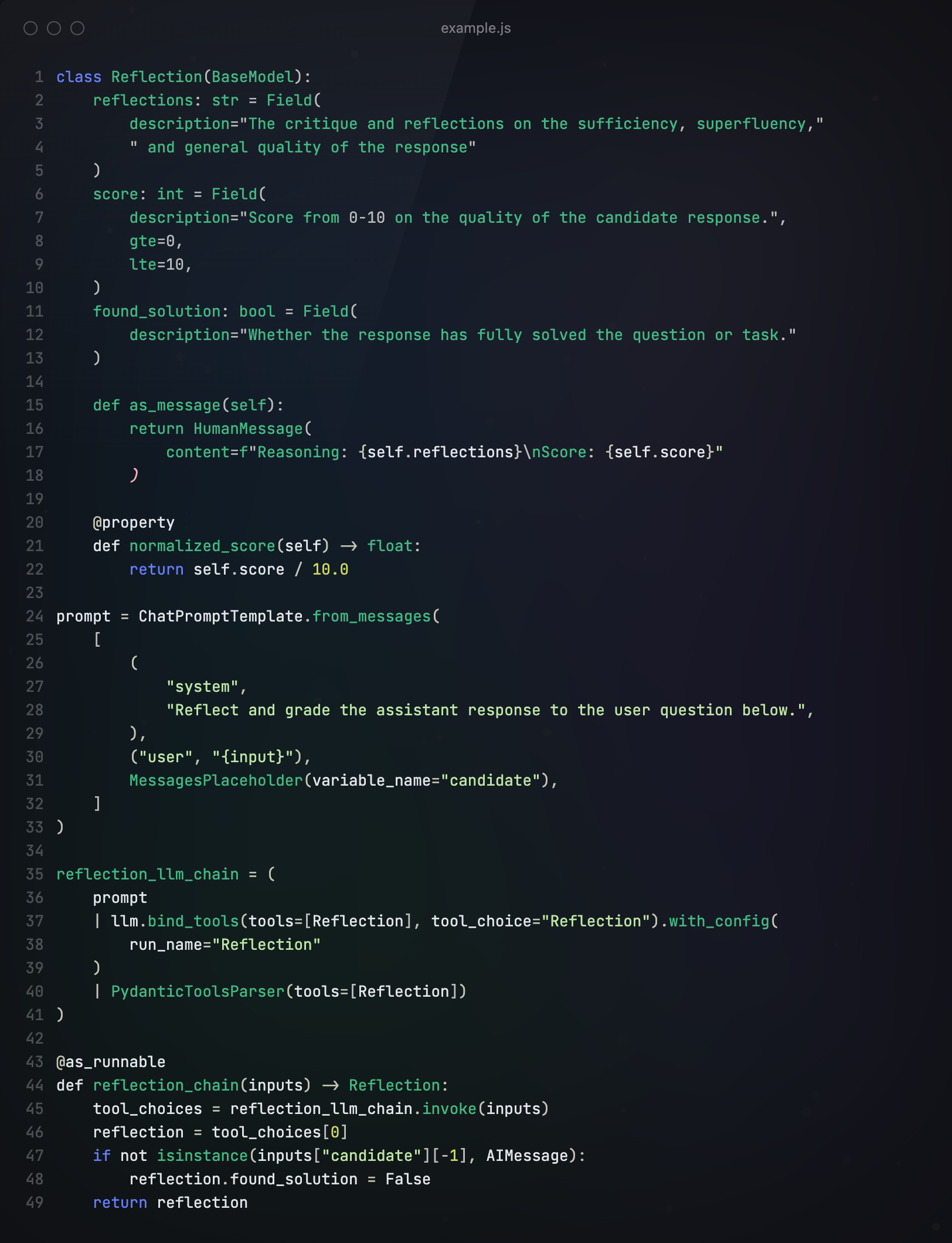
然后,构建反射系统,反射系统将根据决策和工具使用结果,对Agent的输出进行打分,我们将在其他两个节点中调用此方法。
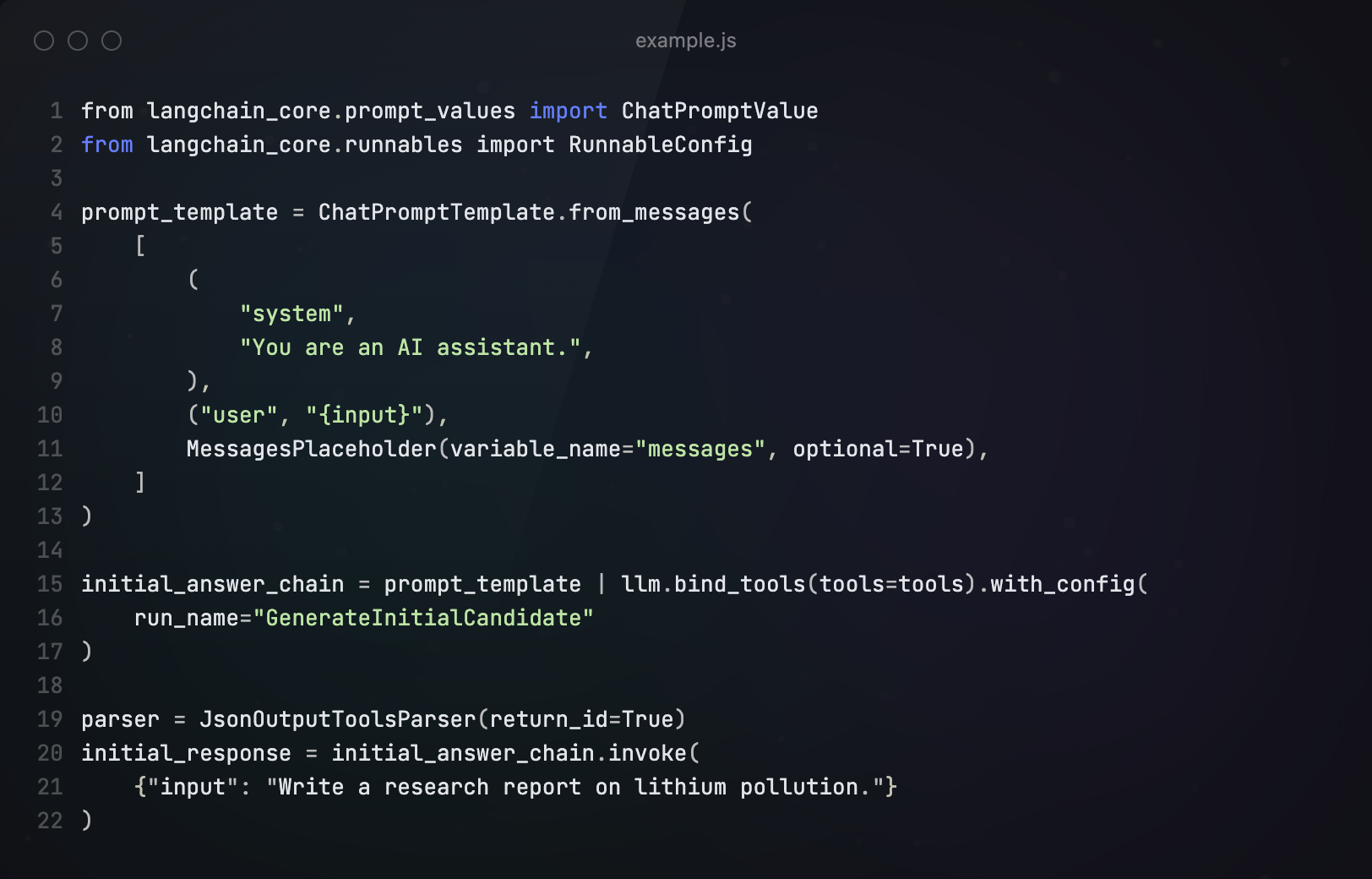
接下来,我们从根节点开始,根据用户输入进行响应
然后开始根节点,我们将候选节点生成和reflection打包到单个节点中。
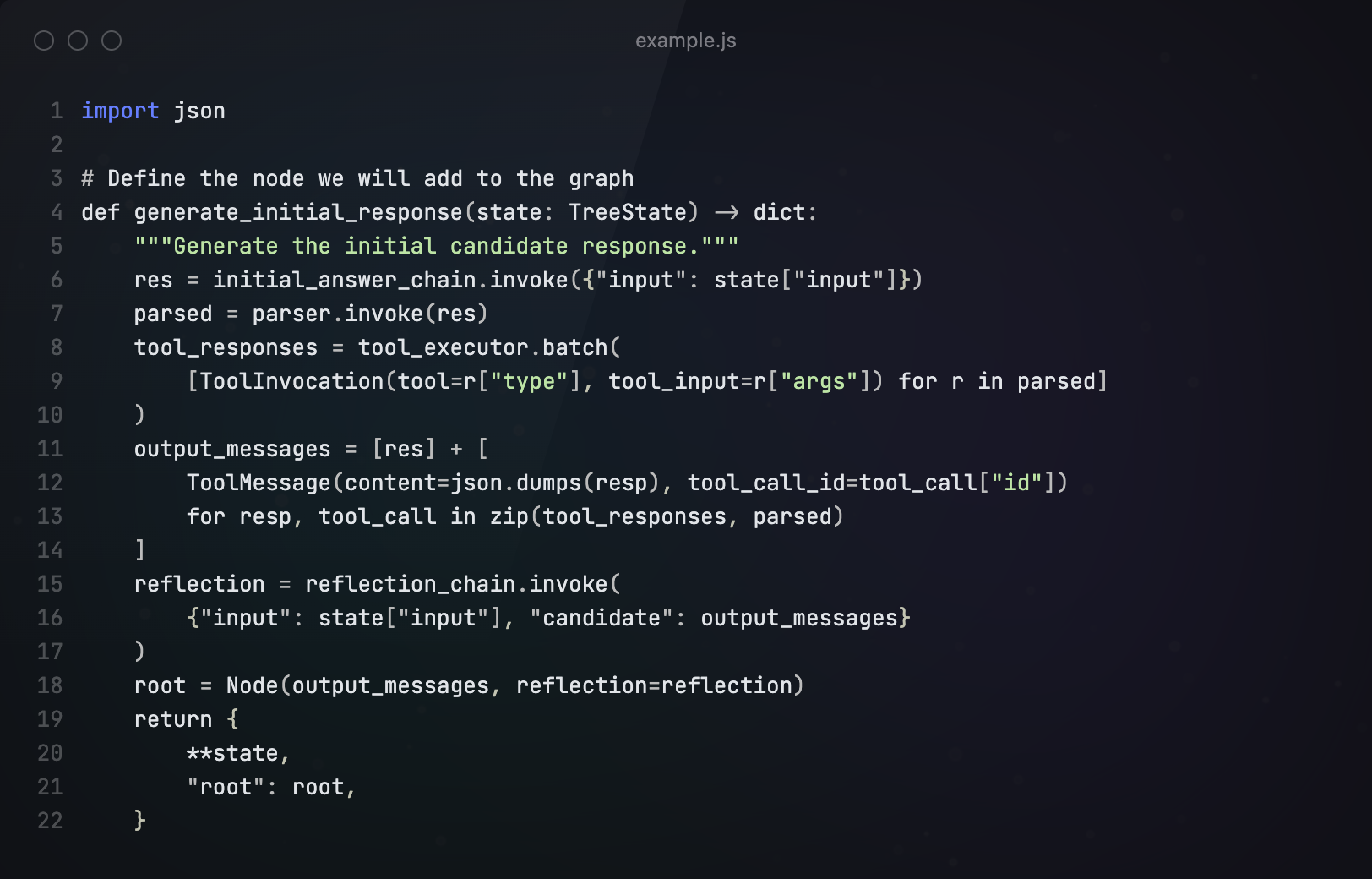
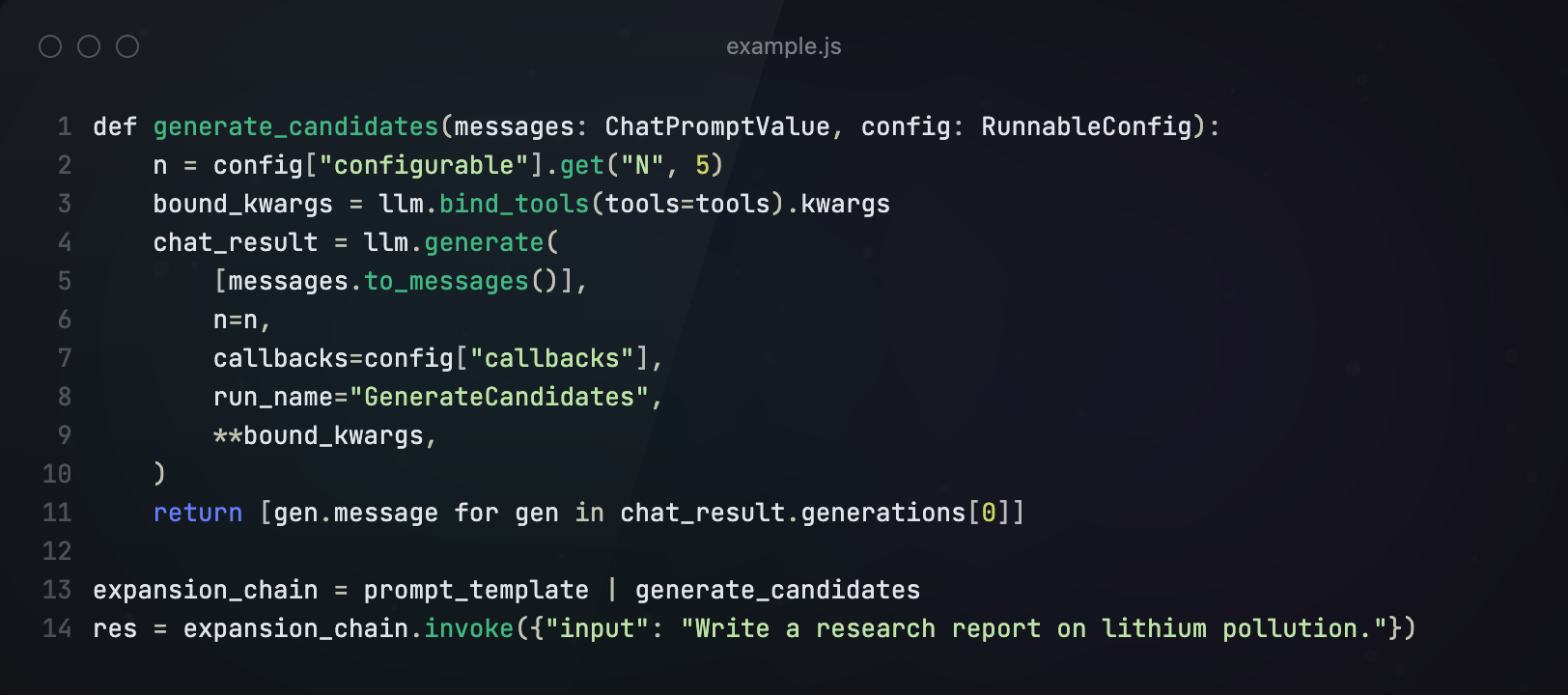
第三步 生成候选节点
对于每个节点,生成5个待探索的候选节点。
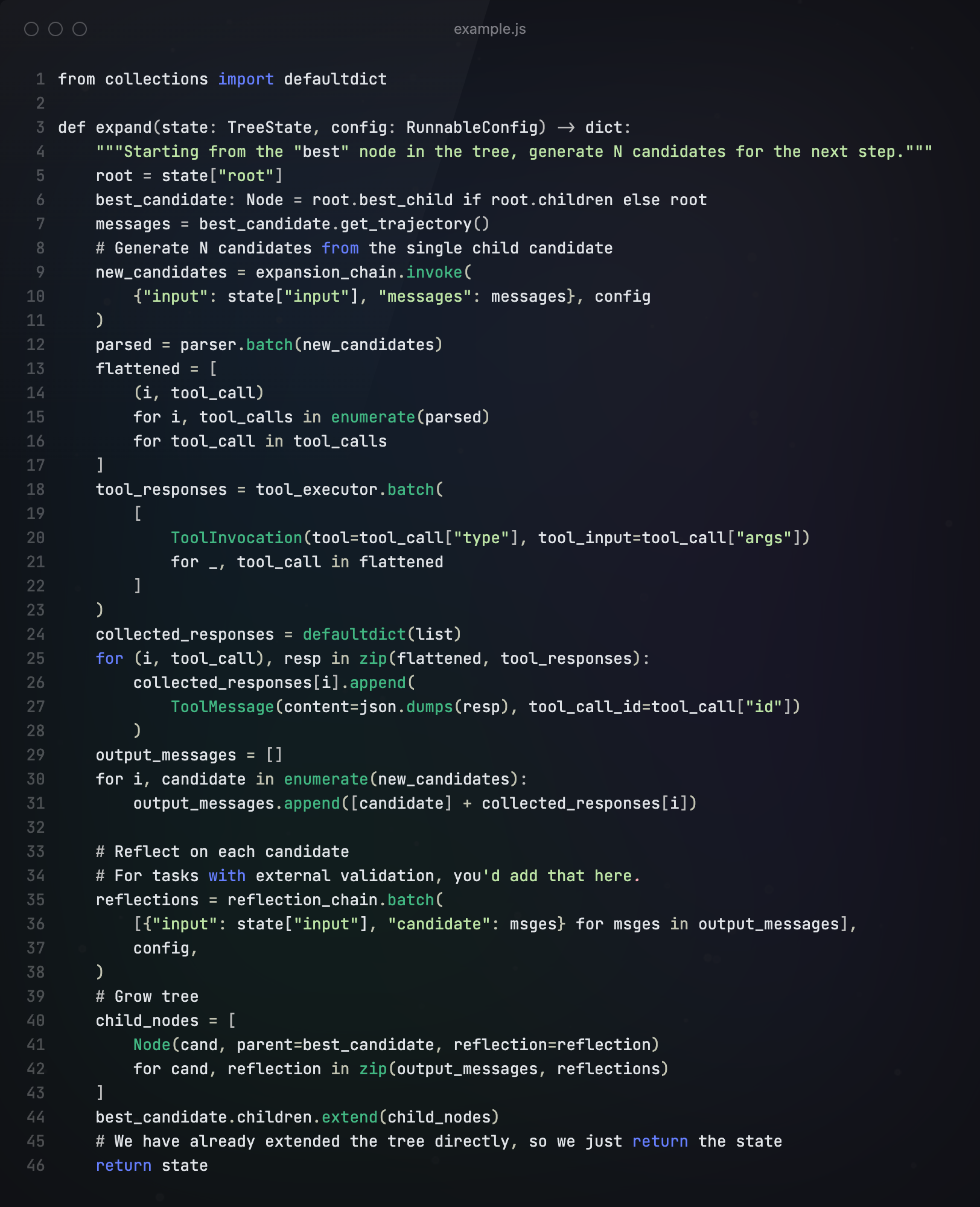
将候选节点生成和refleciton步骤打包在下面的扩展节点中,所有操作都以批处理的方式进行,以加快执行速度。
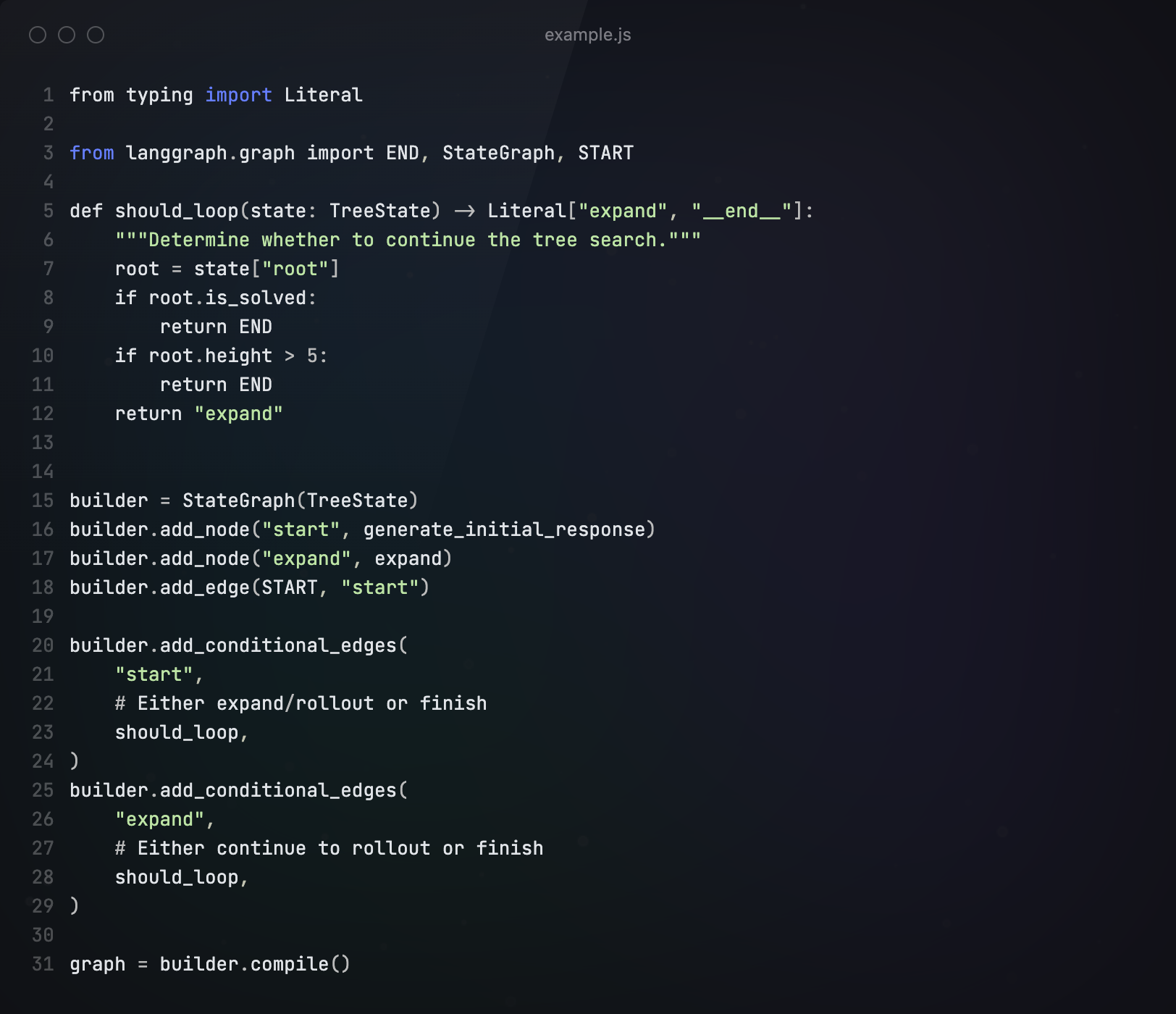
第四步 构建流程图
下面,我们构建流程图,将根节点和扩展节点加入进来
至此,整个LATS的核心逻辑就介绍完了。关注公众号【风叔云】,回复关键词【LATS源码】,可获取LATS设计模式的完整源代码。
总结
与其他基于树的方法相比,LATS实现了自我反思的推理步骤,显著提升了性能。当采取行动后,LATS不仅利用环境反馈,还结合来自语言模型的反馈,以判断推理中是否存在错误并提出替代方案。这种自我反思的能力与其强大的搜索算法相结合,使得LATS更适合处理一些相对复杂的任务。
然而,由于算法本身的复杂性以及涉及的反思步骤,LATS通常比其他单智能体方法使用更多的计算资源,并且完成任务所需的时间更长。
后记
这篇文章之后,整个《AI大模型实战篇》系列就全部介绍完了,这个系列一共包括八篇文章,从最经典的ReAct模式开始,沿着规划路线介绍了REWOO、Plan&Execute和LLM Compiler,沿着反思路线介绍了Basic Reflection、Self Discover和Reflexion,并以最强大的设计模式LATS作为收尾。整个系列基本上包含了目前AI大模型和AI Agent的全部主流设计框架,后续如果有新的前沿设计模式和具体案例,风叔还会零星做一些介绍。
但是,所有的这些设计模式,都只是在告诉AI Agent应该如何规划和思考,且只能依赖于大模型既有的知识储备。而实际应用中,我们往往更希望AI Agent结合我们给定的知识和信息,在更专业的垂直领域内进行规划和思考。
比如我们希望Agent帮我们做论文分析、书籍总结,或者在企业级场景中,让AI Agent写营销计划、内部知识问答、智能客服等等非常多的场景,只靠上面几种Agent设计模式是远远不够的,我们必须给大模型外挂知识库,并且通过工作流进一步约束和规范Agent的思考方向和行为模式。
解决这个问题的最佳方式是利用Rag技术,接下来我们正式开启《Rag系统实战篇》系列。在后续的几篇文章中,风叔将同样结合应用场景和源代码,详细介绍Rag系统的实现方式和优化技巧。
对于还不太了解Rag的读者,可以先参考风叔的这两篇文章进行预习。
《聊聊炙手可热的Rag:产生原因、基本原理与实施路径》
《Rag系统的发展历程,从朴素、高级到模块化》
作者:风叔
来源:风叔云
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫 
